Datengestützte Wohnlagenanalyse – ein Open-Source-Projekt auf GitHub
Im vergangenen Semester haben Studierende der Wirtschaftsinformatik an der Technischen Hochschule Brandenburg im Rahmen eines Praxisprojekts eine spannende Fragestellung bearbeitet:
Wie lassen sich Wohnlagen innerhalb einer Stadt objektiv und datenbasiert bewerten?
Hintergrund war die Diskussion um Mietspiegel und Wohnlagenklassen, die üblicherweise von Kommunen und Gutachterausschüssen anhand von Kriterien wie Zentrumsnähe oder Lärmbelastung eingeteilt werden. Doch wie valide und nachvollziehbar sind diese Einteilungen? Und wie könnten moderne Methoden der Datenanalyse hier mehr Transparenz schaffen?
Vom Praxisprojekt zur Musterlösung
Unter dem Titel „Praxis-Projekt: Datengesteuerte Einstufung von Wohnlagen“ haben die Studierenden Daten zu Lärm, Erreichbarkeit von Ärzten und Supermärkten, Entfernungen zum Zentrum und weitere Faktoren verarbeitet.
Über Meetingpoint Brandenburg wurde bereits über die Ergebnisse berichtet.
Um die Ideen weiterzuführen und auch für die Öffentlichkeit nutzbar zu machen, habe ich im Anschluss eine Musterlösung entwickelt, die die Ansätze bündelt und in einem reproduzierbaren Code-Paket verfügbar macht.
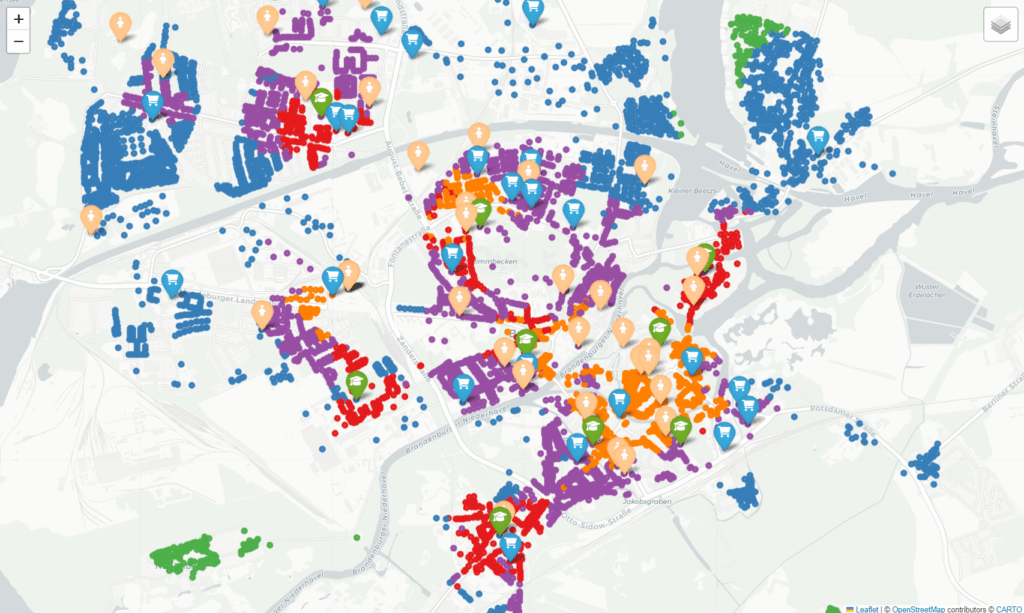
Das Ergebnis steht nun auf GitHub bereit: https://github.com/AndreNitze/WohnlagenBRB
Bewertete Kriterien
In der aktuellen Version des Projekts werden folgende Faktoren berücksichtigt:
- Zentrumsnähe – Distanz zum Stadtzentrum
- Lärmbelastung – basierend auf Umwelt- und Verkehrsdaten
- medizinische Versorgung – Erreichbarkeit von Arztpraxen
- Einzelhandel & Versorgung – Anzahl und Nähe von Supermärkten
- ÖPNV-Taktung – Häufigkeit der Abfahrten an der nächsten ÖPNV-Haltestelle (“Headway”)
Die Kriterien werden standardisiert (z-Werte) und anschließend mithilfe von K-Means-Clustering zu Wohnlagenklassen gruppiert.
Technische Umsetzung
Das Projekt ist als Jupyter-Notebook umgesetzt und nutzt Python-Bibliotheken aus dem Bereich der Datenanalyse und Geoinformation. Wichtige Bausteine sind:
- K-Means-Clustering zur automatischen Gruppierung von Wohnlagen
- z-Werte zur relativen Bewertung einzelner Merkmale
- GeoPandas & Folium zur Visualisierung in Kartenform
- flexible Erweiterbarkeit um neue Kriterien (z. B. ÖPNV-Qualität, Bahnübergänge, Bildungseinrichtungen)
Damit können Interessierte selbst nachvollziehen, wie sich aus offenen Geodaten ein systematisches Wohnlagenmodell für Brandenburg an der Havel ableiten lässt.
Perspektiven und Einsatzmöglichkeiten
Die Musterlösung ist bewusst so gestaltet, dass sie übertragbar auf andere Städte ist. Mit entsprechend aufbereiteten Adress- und Umgebungsdaten lässt sich das Modell schnell anpassen.
Besonders interessant sind folgende Perspektiven:
- Kommunale Anwendungen zur Validierung oder Ergänzung offizieller Wohnlagenklassifikationen
- Lehre und Forschung im Bereich Data Science, Stadtentwicklung und Geoinformatik
- Diskussion in der Öffentlichkeit, wie Datenmethoden zu mehr Nachvollziehbarkeit bei sensiblen Themen wie Mietspiegeln beitragen können
Für mich ist das Projekt ein schönes Beispiel, wie Studierendenprojekte, angewandte Forschung und Open Source ineinandergreifen können: Von der Idee über die Umsetzung im Semester bis hin zur Veröffentlichung als GitHub-Repository.